Thank you, ChatGPT!!!
I have been suspicious of ChatGPT, considering aspects that Chomsky and his co-authors mentioned in a NY Times article.
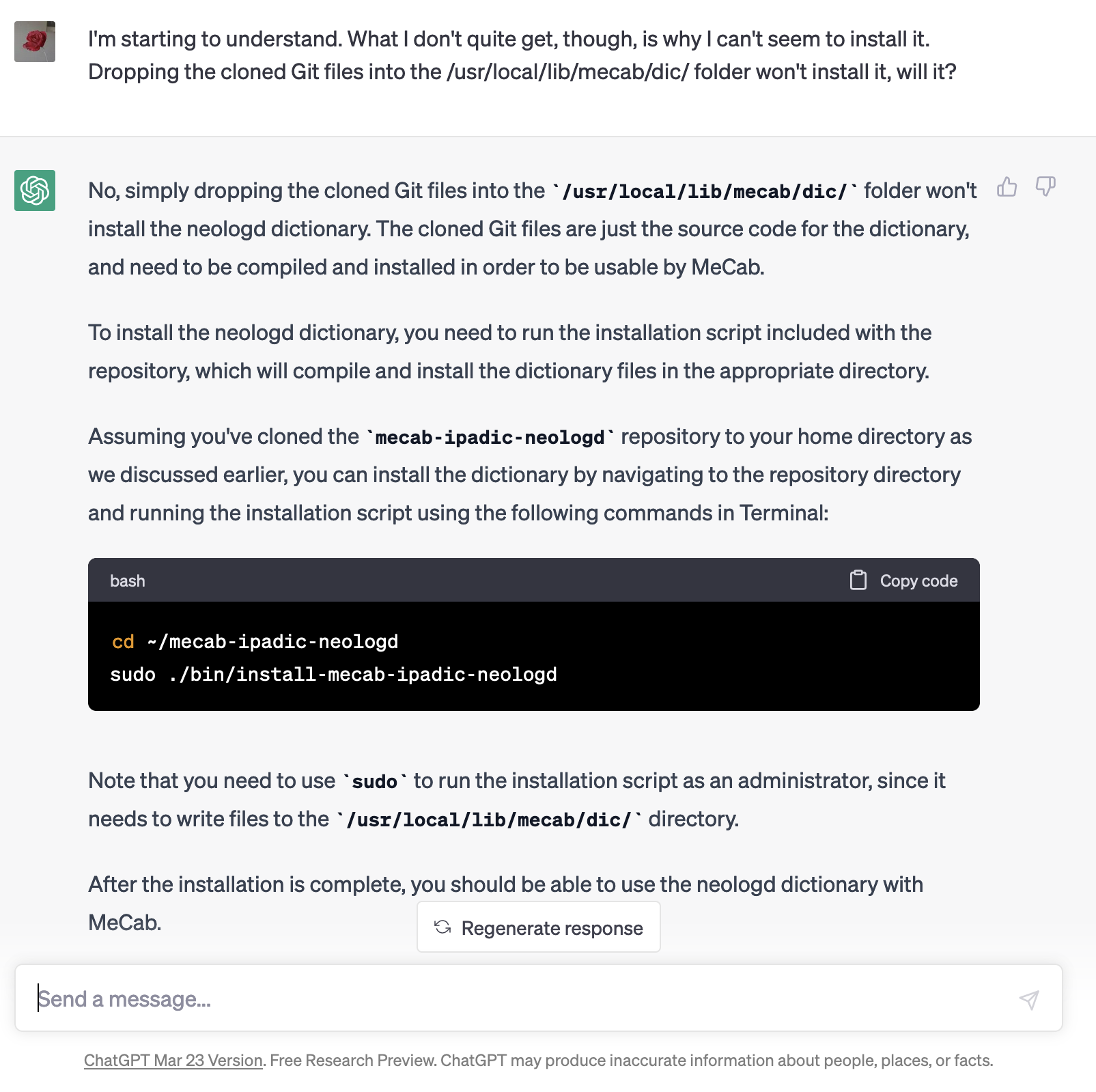
Then two weeks ago I got really stuck using Terminal on my Mac to install a neologism dictionary for processing Japanese called neologd. I may be a digital humanist, but I really prefer the theory to the actual computing. It can be so hard to get a computer to work the way I want it to! ![]()
Googling all my questions didn’t produce answers specific to my problem. Asking for help in the Github Issue forum for the dictionary didn’t get me much of a response. Then, one night as I was falling asleep I remembered reports of people saying they had used ChatGPT to check code.
Success! I could ask ChatGPT all of my newbie questions and didn’t have to worry about taking up someone’s time. Sure, not all of the answers were accurate, but working with ChatGPT eventually helped me identify my problem and fix it.
To follow my process of frustration and a summary of the results, see the Github Issue I opened for neologd two weeks ago and closed just earlier.
While some might say IT helpdesk personell might be out of a job, for computing problems with open-source software like this dictionary, ChatGPT can be a really useful tool for troubleshooting as well as for learning computing structures and code.



